Tensorflow 实现 Multilayer Perceptron(多层感知器) 模型
下面开始用 Tensorflow 实现 Multilayer Perceptron(多层感知器) 模型
这里数据使用的是实战(一)和实战(二)中的 MNIST 的图片分类数据
1.导入 tensorflow 包并下载 MNIST 数据
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
import tensorflow as tf
首先也准备数据,如果本地已经下载好了数据,input_data下的read_data_sets则不会重新下载数据,而是将数据加载进来。
这里用到的 tensorflow 版本为 1.0.0,其他版本没有测试。
2.定义训练参数和网络参数
# Parameter
learning_rate = 0.001
training_epochs = 15
batch_size = 100
display_step = 1
# Network Parameters
n_hidden_1 = 256 # 1st layer number of features
n_hidden_2 = 256 # 2nd layer number of features
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
参数说明:
- 训练时的参数,比如学习率、训练轮数、训练批次的大小和结果显示的步长
- 网络结构参数,隐藏层的单元数、网络的输入和输出数
3.定义模型的输入、输出
# tf Graph Input
x = tf.placeholder("float", [None, n_input])
y = tf.placeholder("float", [None, n_classes])
这里用 placeholder 来装载输入、输出变量,格式为 float
- x: 训练数据集,维度为 _ * 784 (MNIST 的图像shape 为 28*28)
- y: 测试数据集,维度 _ * 10 (这里对应的是0-9的10分类问题)
4.定义网络的权重和偏置
# store layers weight and bias
weights = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
因为网络中有两个隐藏层h1、h2和一个输出层out,其中hidden layer1的输出作为hidden layer2的输入,hidden layer2的输出作为out layer的输入。 偏置项是一个一维的向量,维度等于各层的神经元个数。
参数通过tf的Variable来定义,采用random_normal(正态、随机)对tensor进行初始化。
5.定义Multilayer Perceptron模型
# Create model
def multilayer_perceptron(x, weights, biases):
# Hidden layer with RELU activation
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
# Hidden layer with RELU activation
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
# Output layer with linear activation
out_layer = tf.matmul(layer_2, weights['out']) + biases['out']
return out_layer
可以看到hidden layer1 和 hidden layer2 的定义除了输入输出的维度不同,其它都是相同的。其实就是:
并用了Relu对输出进行激励。Relu(激励函数)可以理解为对于输出的一种强化,来看一下Relu的曲线:
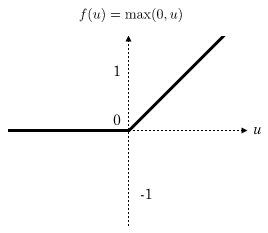
可以理解为对于大于阈值就保留,而小于阈值就置为0。
6.定于模型的损失函数、优化策略
# Construct model
pred = multilayer_perceptron(x, weights, biases)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# Initializiing the variables
init = tf.global_variables_initializer()
- 损失函数:采用的是交叉熵损失函数
- 优化函数:采用的是Adam,还有多种不同的优化器供选择。(可以参考http://blog.csdn.net/liyuan123zhouhui/article/details/68946448这篇博文,里面对各种优化器有很好的介绍)
7.模型运行和结果输出
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={x: batch_x, y: batch_y})
# Compute average loss
avg_cost += c/total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print("Epoch:", "%04d" % (epoch+1), 'cost=','{:.9f}'.format(avg_cost))
print ("Optimization Finished")
# Test Model
correct_prediction = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
# calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print ("Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))
最终Multilayer Perceptron模型在测试数据集上的准确率可以达到0.944
- Accuracy: Accuracy: 0.944
比用tensorflow实现的传统模型具有更好的准确率。