CNN 实现文本分类
1、什么是CNN?
CNN 的全称是 Convolutional Neural Networks, 中文名称叫卷积神经网络。从名称上可以知道CNN是神经网络,还是一种加上了卷积的神经网络。
知道了CNN的定义,就来看看到底CNN到底什么样?以及CNN到底能干什么事?
既然叫神经网络,那么就说明肯定是由一些基础单元(cell)构成的,下面图显示了一个神经单元的基本结构。

可能大家看这个图又疑惑了,什么啊?几条线加一个圈?其实上面这个图可以用下面的公式表示:
最右侧的输出\(O\)等于最左侧的输入 $x_i$ 乘上对应的系数 $\omega_i$ ,然后对所有的乘积进行加权,加权后整体作为函数$f()$的输入。这里的$f()$叫做激励函数,在这里理解成输入到输出的一种映射关系即可。
可能有些同学看到这里会想,这不就是一个线性回归方程嘛!是的,可以这样理解,最基础的神经单元就是在线性回归方程外面包上一层激活函数。
有了这样的概念,后面就好理解多了,神经网络其实就是由许许多多这样的神经元组成的。

上面的图是一个最最普遍的神经网络结构,包含一个输入层(input layer)、一个输出层(output layer)以及三个隐藏层(hidden layer1、hidden layer2、hidden layer3)。其中,这里的每一层就是由上面的神经单元构成的。
CNN(卷积神经网络)其实和上面图中的神经网络没有本质上的区别,也是由基础的神经单元构成层(layer),然后再由不同的layer构成一个完整的网络。只是CNN中的层做了相应的处理。
比如说:
- 卷积层(Convolutional layer)
- 池化层(Pooling layer)
- 全连接层(Fully connected layer)

先记住这些概念,后面会告诉大家这些层都是做什么用的。知道了CNN长什么样子,那就来说CNN能干什么吧!

上面这张图是一个CNN用于图片分类的实例,左侧的图片作为神经网络的输入,然后网络的输出是这张图片对应的类别。在这里输出的就是_car_,很显然分对了。
2、 Convolutional (卷积)
首先要明确卷积的含义: 简而言之就是__一个函数在另一个函数上的加权叠加。__
卷积在信号处理一些领域用的很多,在这里只需要先大致上知道它是一种加权叠加即可。知乎上有一个回答解答的很好,有兴趣的点这看答案,可以帮助大家很好的理解。
明白了卷积的概念,再来看在Convolutional Neural Networks里卷积的作用是什么?

上面的图是对一张图片进行卷积的示意图,最左侧是一张图片的数值(7x7)表示,中间的3x3矩阵是Convolutional Kernel(卷积核)。
卷积的过程其实就是用卷积核矩阵去原始图片进行相同位置的元素进行乘积并累加,将累加值返回的过程。下面的动图可以演示这一过程:

怎么样?卷积也不过如此吧?哈哈~
还是看不懂!那点这个,继续看。
3、Pooling (池化)
Pooling,也就是池化,名称很洋气,但其实就是一种维度变换(Dimensional Scale)。
一张图讲清楚到底什么是池化:
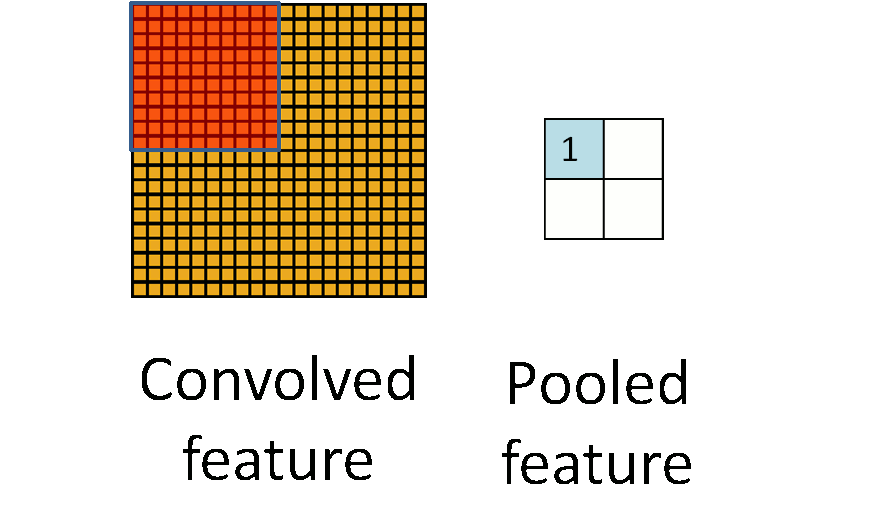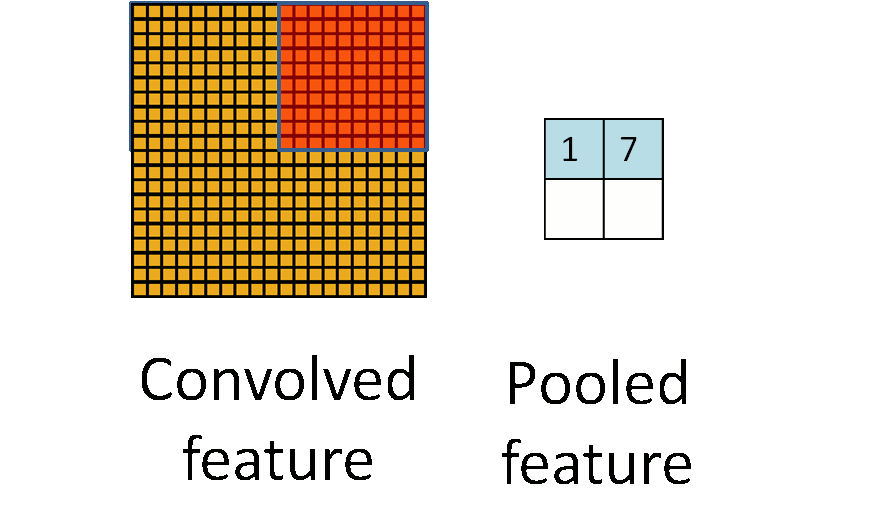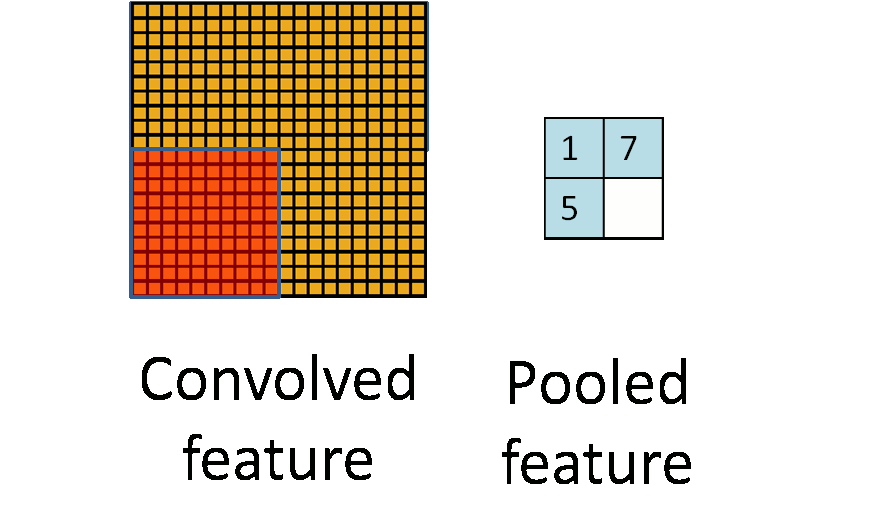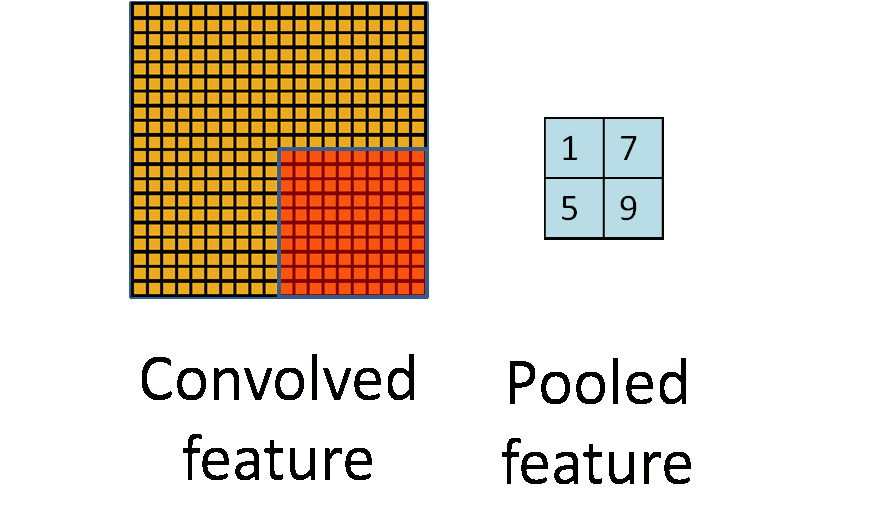
左面的图是卷积后获得Feature Map,每个黄色的小格子就是一个卷积获得的特征值,可以看出来,图片上有很多这样的小格子,但是在实际的图片处理中可能有比这个还要多的小格子,这样就带了问题,什么问题呢?训练的时候这一层的参数会有很多,而神经网络又是多层的,这样整个网络的参数数量就非常巨大。对于这种情况,大神们就研究出了Pooling这种东西。
那么要怎么做呢?简单点,假设把左侧的黄图分成等分成四个区域,然后在每个区域里挑出一个特征值来代替这个区域,那么左面的图就可以用右边的2x2区域来代替。这样参数一下就剩下了4个。
Pooling大致的作用就是如此,至于更详细的解释,老办法点这自己看。
4、 Activation Function (激励函数)
在前面介绍神经元时候提到了Activation Funciton,就是$f()$,现在就来说说它到底是什么!
前面已经说过了,神经元的输出 $O$ 等于将输入的线性加权输入到$f()$ 后的结果值。这就有意思,直接等于线性加权不行吗?还非得把线性加权输入到$f()$里?
答案其实并不是不行,但是通常不这样来做,为什么?
首先这里给 Activation Function 一个定义: Activation Function 是一种非线性变换。
这里来解释原因,如果不对输入的线性加权进行非线性变换,那么神经网络的每层都只是在做线性变换,多层输入叠加之后也还是线性变换。而线性模型的表达能力不够,对于很多的实际场景都没有办法解决,使用激励函数可以引入非线性的因素。

体现在上面的图片中就是,如果不加入Activation Function则只能有直线来分割平面的区域。而加入Activation Function则可以使用曲线来分割平面的区域。
5、 CNN 文本分类处理

上面这张图出自Yoon Kim 的论文,目前所有的CNN在文本上的应用都基于此。
5.1、 输入层
如图所示,输入层是句子中的词语对应的 vector 依次(从上到下)排列的矩阵,假设句子有 n 个词,vector 的维数为 k , 那么这个矩阵就是 n × k 的(在 CNN 中可以看作一副高度为 n、宽度为 k 的图像)。
这个矩阵的类型可以是静态的(static),也可以是动态的(non static)。
- 静态就是词的 vector 是固定不变的;
- 动态则是在模型训练过程中,词的 vector 也当做是可优化的参数,通常把反向误差传播导致词的 vector 中值发生变化的这一过程称为Fine tune。(这里如果词的 vector 如果是随机初始化的,不仅训练得到了CNN分类模型,还得到了word2vec这个副产品,如果已经有训练的词的 vector,那么其实是一个迁移学习的过程)
对于未登录词的vector,可以用0或者随机小的正数来填充。
5.2、 卷积层
输入层通过卷积操作得到若干个Feature Map,卷积窗口的大小为 h × k ,其中 h 表示纵向词语的个数,而 k 表示词的 vector 的维数。通过这样一个大型的卷积窗口,将得到若干个列数为1的Feature Map。(熟悉NLP中N-GRAM模型的读者应该懂得这个意思)。
5.3、 池化层
接下来的池化层,文中用了一种称为 Max-over-timePooling 的方法。这种方法就是简单地从之前一维的 Feature Map 中提出最大的值,文中解释最大值代表着最重要的信号。可以看出,这种 Pooling 方式可以解决可变长度的句子输入问题(因为不管 Feature Map 中有多少个值,只需要提取其中的最大值)。最终池化层的输出为各个Feature Map 的最大值们,即一个一维的向量。
5.4、 Fully Connected + SoftMax 层
池化层的一维向量的输出通过全连接的方式,连接一个Softmax层,Softmax层可根据任务的需要设置(通常反映着最终类别上的概率分布)。
6、 Tensorflow 实现 CNN
写这篇文章的初衷其实是帮助大家理解 CNN 在 Text Classification 上的应用,所以我不想大家只是浅显的知道一些概念,过后对于 CNN 仍然一知半解。下面,我用一个完整的 CNN 用于文本分类的代码给大家演示具体如何用 CNN 来做文本分类。
所有的代码都是在如下环境完成:
python 3.5 tensorflow 1.0.0
首先看一下数据集的格式:

在网上随便找的1000条文本,里面包含了三个主题,对应着:
What When Who
中文文本的处理方式略微有一些差别,因为需要进行分词。
首先,建立一个脚本将dataset按照不同的主题分成三个数据集。
'''
Created on Thursday July
__author__ : 'jdlimingyang@jd.com'
'''
import re
def clean_str(string):
"""
Tokenization/string cleaning for all datasets except for SST.
Original taken from https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py
"""
string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'re", " \'re", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
return string.strip().lower()
def main():
file_path = 'C:\\Users\\jrlimingyang\\PycharmProjects\\question_classifier_cnn\\corpus\\QA_set.txt'
dataset = list(open(file_path,'r').readlines())
dataset = [s.strip() for s in dataset]
dataset = [clean_str(sent) for sent in dataset]
x_text = [s.split(' ') for s in dataset]
dataset = [s[2:] for s in x_text]
dataset_clean = []
for s in dataset:
dataset_clean.append([' '.join(ww for ww in s)])
for s in dataset_clean:
for w in s:
if 'who' in w:
f = open('C:\\Users\\jrlimingyang\\PycharmProjects\\question_classifier_cnn\\corpus\\qa_data.who', 'a').write(w + '\n')
if 'what' in w:
f = open('C:\\Users\\jrlimingyang\\PycharmProjects\\question_classifier_cnn\\corpus\\qa_data.what', 'a').write(
w + '\n')
if 'when' in w:
f = open('C:\\Users\\jrlimingyang\\PycharmProjects\\question_classifier_cnn\\corpus\\qa_data.when', 'a').write(
w + '\n')
if 'affirmation' in w:
f = open('C:\\Users\\jrlimingyang\\PycharmProjects\\question_classifier_cnn\\corpus\\qa_data.affirmation', 'a').write(
w + '\n')
if __name__=='__main__':
main()
数据集划分完成后,产生下面的三个文件:
qa_data.what qa_data.when qa_data.who
有了上面不同主题的文件,接下来对文件进行分词和添加标签等操作。
'''
Created on Thursday July
__author__ : 'jdlimingyang@jd.com'
'''
import numpy as np
import re
import itertools
from collections import Counter
def clean_str(string):
"""
Tokenization/string cleaning for all datasets except for SST.
Original taken from https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py
"""
string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'re", " \'re", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
return string.strip().lower()
def load_data_and_labels():
'''
加载类别数据,分词并添加标签
return: 分词后的句子 和 对定的标签
'''
who_examples = list(open('C:\\Users\\jrlimingyang\\PycharmProjects\\question_classifier_cnn\\corpus\\qa_data.who', 'r').readlines())
who_examples = [s.strip() for s in who_examples]
when_examples = list(open('C:\\Users\\jrlimingyang\\PycharmProjects\\question_classifier_cnn\\corpus\\qa_data.when', 'r').readlines())
when_examples = [s.strip() for s in when_examples]
what_examples = list(open('C:\\Users\\jrlimingyang\\PycharmProjects\\question_classifier_cnn\\corpus\\qa_data.what', 'r').readlines())
what_examples = [s.strip() for s in what_examples]
# Split by words
x_text = who_examples + when_examples + what_examples
x_text = [clean_str(sent) for sent in x_text]
x_text = [s.split(" ") for s in x_text]
# Generate labels
who_labels = [[1, 0, 0] for _ in who_examples]
when_labels = [[0, 1, 0] for _ in when_examples]
what_labels = [[0, 0, 1] for _ in what_examples]
y = np.concatenate([who_labels, when_labels, what_labels], 0)
return [x_text, y]
def pad_sentences(sentences, padding_word="<PAD/>"):
"""
Pads all sentences to the same length. The length is defined by the longest sentence.
Returns padded sentences.
"""
sequence_length = max(len(x) for x in sentences)
padded_sentences = []
for i in range(len(sentences)):
sentence = sentences[i]
num_padding = sequence_length - len(sentence)
new_sentence = sentence + [padding_word] * num_padding
padded_sentences.append(new_sentence)
return padded_sentences
def build_vocab(sentences):
"""
Builds a vocabulary mapping from word to index based on the sentences.
Returns vocabulary mapping and inverse vocabulary mapping.
"""
# Build vocabulary
word_counts = Counter(itertools.chain(*sentences))
# Mapping from index to word
vocabulary_inv = [x[0] for x in word_counts.most_common()]
vocabulary_inv = list(sorted(vocabulary_inv))
# Mapping from word to index
vocabulary = {x: i for i, x in enumerate(vocabulary_inv)}
return [vocabulary, vocabulary_inv]
def build_input_data(sentences, labels, vocabulary):
"""
Maps sentencs and labels to vectors based on a vocabulary.
"""
x = np.array([[vocabulary[word] for word in sentence] for sentence in sentences])
y = np.array(labels)
return [x, y]
def load_data():
"""
Loads and preprocessed data for dataset.
Returns input vectors, labels, vocabulary, and inverse vocabulary.
"""
# Load and preprocess data
sentences, labels = load_data_and_labels()
sentences_padded = pad_sentences(sentences)
vocabulary, vocabulary_inv = build_vocab(sentences_padded)
x, y = build_input_data(sentences_padded, labels, vocabulary)
return [x, y, vocabulary, vocabulary_inv]
def batch_iter(data, batch_size, num_epochs, shuffle=True):
"""
Generates a batch iterator for a dataset.
"""
data = np.array(data)
data_size = len(data)
num_batches_per_epoch = int(len(data) / batch_size) + 1
for epoch in range(num_epochs):
# Shuffle the data at each epoch
if shuffle:
shuffle_indices = np.random.permutation(np.arange(data_size))
shuffled_data = data[shuffle_indices]
else:
shuffled_data = data
for batch_num in range(num_batches_per_epoch):
start_index = batch_num * batch_size
end_index = min((batch_num + 1) * batch_size, data_size)
yield shuffled_data[start_index:end_index]
# x_test, y_test, vocabulary, vocabulary_inv = load_data()
上面的函数主要是完成了文本的分词、打标签,并生成一个batch data的迭代器。
做完上面的准备工作之后,就可以建立基于CNN的文本分类模型。
'''
Created on Thursday July
__author__ : 'jrlimingyang@jd.com'
'''
import tensorflow as tf
import numpy as np
class TextCNN(object):
"""
A CNN for text classification.
Uses an embedding layer, followed by a convolutional, max-pooling and softmax layer.
"""
def __init__(
self, sequence_length, num_classes, vocab_size,
embedding_size, filter_sizes, num_filters, l2_reg_lambda=0.0):
# Placeholders for input, output and dropout
self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# Keeping track of l2 regularization loss (optional)
l2_loss = tf.constant(0.0)
# Embedding layer
with tf.device('/cpu:0'), tf.name_scope("embedding"):
W = tf.Variable(
tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0),
name="W")
self.embedded_chars = tf.nn.embedding_lookup(W, self.input_x)
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
# Create a convolution + maxpool layer for each filter size
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
self.embedded_chars_expanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs.append(pooled)
# Combine all the pooled features
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(pooled_outputs, 3)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
# Add dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
# Final (unnormalized) scores and predictions
with tf.name_scope("output"):
W = tf.get_variable(
"W",
shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")
# CalculateMean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(labels=self.input_y, logits=self.scores)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
# Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
模型的构建主要有以下的几个步骤:
1、构建embedding layer 2、构建convolutional layer 3、构建max pooling layer 4、选择一个合适的优化器
所有准备工作完成之后就可以开始模型的训练。
'''
Created on Thursday July
__author__ : 'jrlimingyang@jd.com'
'''
import tensorflow as tf
import numpy as np
import os
import time
import datetime
import corpus_handle
from text_cnn import TextCNN
# Parameters
# ==================================================
# Model Hyperparameters
tf.flags.DEFINE_integer("embedding_dim", 128, "Dimensionality of character embedding (default: 128)")
tf.flags.DEFINE_string("filter_sizes", "3,4,5", "Comma-separated filter sizes (default: '3,4,5')")
tf.flags.DEFINE_integer("num_filters", 128, "Number of filters per filter size (default: 128)")
tf.flags.DEFINE_float("dropout_keep_prob", 0.5, "Dropout keep probability (default: 0.5)")
tf.flags.DEFINE_float("l2_reg_lambda", 0.0, "L2 regularizaion lambda (default: 0.0)")
#
## Training parameters
tf.flags.DEFINE_integer("batch_size", 30, "Batch Size (default: 64)")
tf.flags.DEFINE_integer("num_epochs", 10, "Number of training epochs (default: 200)")
tf.flags.DEFINE_integer("evaluate_every", 100, "Evaluate model on dev set after this many steps (default: 100)")
tf.flags.DEFINE_integer("checkpoint_every", 100, "Save model after this many steps (default: 100)")
## Misc Parameters
tf.flags.DEFINE_boolean("allow_soft_placement", True, "Allow device soft device placement")
tf.flags.DEFINE_boolean("log_device_placement", False, "Log placement of ops on devices")
FLAGS = tf.flags.FLAGS
FLAGS._parse_flags()
print("\nParameters:")
for attr, value in sorted(FLAGS.__flags.items()):
print("{}={}".format(attr.upper(), value))
print("")
# Data Preparatopn
# ==================================================
# Load data
print("Loading data...")
x, y, vocabulary, vocabulary_inv = corpus_handle.load_data()
# Randomly shuffle data
np.random.seed(10)
shuffle_indices = np.random.permutation(np.arange(len(y)))
x_shuffled = x[shuffle_indices]
y_shuffled = y[shuffle_indices]
# Split train/test set
# TODO: This is very crude, should use cross-validation
x_train, x_dev = x_shuffled[:-10], x_shuffled[-10:]
y_train, y_dev = y_shuffled[:-10], y_shuffled[-10:]
print("Vocabulary Size: {:d}".format(len(vocabulary)))
print("Train/Dev split: {:d}/{:d}".format(len(y_train), len(y_dev)))
# Training
# ==================================================
with tf.Graph().as_default():
session_conf = tf.ConfigProto(
allow_soft_placement=FLAGS.allow_soft_placement,
log_device_placement=FLAGS.log_device_placement)
sess = tf.Session(config=session_conf)
with sess.as_default():
cnn = TextCNN(
sequence_length=x_train.shape[1],
num_classes=3,
vocab_size=len(vocabulary),
embedding_size=FLAGS.embedding_dim,
filter_sizes=list(map(int, FLAGS.filter_sizes.split(","))),
num_filters=FLAGS.num_filters,
l2_reg_lambda=FLAGS.l2_reg_lambda)
# Define Training procedure
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(0.001)
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in grads_and_vars:
if g is not None:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)
sparsity_summary = tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
grad_summaries.append(grad_hist_summary)
grad_summaries.append(sparsity_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
# Output directory for models and summaries
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
# Summaries for loss and accuracy
loss_summary = tf.summary.scalar("loss", cnn.loss)
acc_summary = tf.summary.scalar("accuracy", cnn.accuracy)
# Train Summaries
train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph_def)
# Dev summaries
dev_summary_op = tf.summary.merge([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph_def)
# Checkpoint directory. Tensorflow assumes this directory already exists so we need to create it
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables())
# Initialize all variables
sess.run(tf.global_variables_initializer())
def train_step(x_batch, y_batch):
"""
A single training step
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: FLAGS.dropout_keep_prob
}
_, step, summaries, loss, accuracy = sess.run(
[train_op, global_step, train_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
train_summary_writer.add_summary(summaries, step)
def dev_step(x_batch, y_batch, writer=None):
"""
Evaluates model on a dev set
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: 1.0
}
step, summaries, loss, accuracy = sess.run(
[global_step, dev_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
if writer:
writer.add_summary(summaries, step)
# Generate batches
batches = corpus_handle.batch_iter(
list(zip(x_train, y_train)), FLAGS.batch_size, FLAGS.num_epochs)
# Training loop. For each batch...
for batch in batches:
x_batch, y_batch = zip(*batch)
train_step(x_batch, y_batch)
current_step = tf.train.global_step(sess, global_step)
if current_step % FLAGS.evaluate_every == 0:
print("\nEvaluation:")
dev_step(x_dev, y_dev, writer=dev_summary_writer)
print("")
if current_step % FLAGS.checkpoint_every == 0:
path = saver.save(sess, checkpoint_prefix, global_step=current_step)
print("Saved model checkpoint to {}\n".format(path))
这里的数据集很小,很快就可以跑完。程序运行的一些输出如下:

可以看到一些设置的参数,这些参数都是比较随机进行设置的,可以针对模型效果进行不断地优化。

可以看到,开始进行训练时,每个 batch 的 accuracy 才有 0.2+, 但是很快就上升到了 0.7+。

最终模型的 accuracy 都在0.9+, 很多batch都可以达到1.0.
项目完整的代码可以点此下载,大家有兴趣可以下载下来跑一下试试。